🙈 By 单雷 2025-10-28
背景
NJet在做动态化能力设计时,曾利用了基于mqtt消息的event框架,整体实现为利用CoPilot框架实现了一个消息的broker,同时CoPilot ctrl进程作为api server,接收http请求,转化为消息后,发送给沙箱进程做配置验证,验证后,广播给作为消费者的所有的worker进程应用配置变更
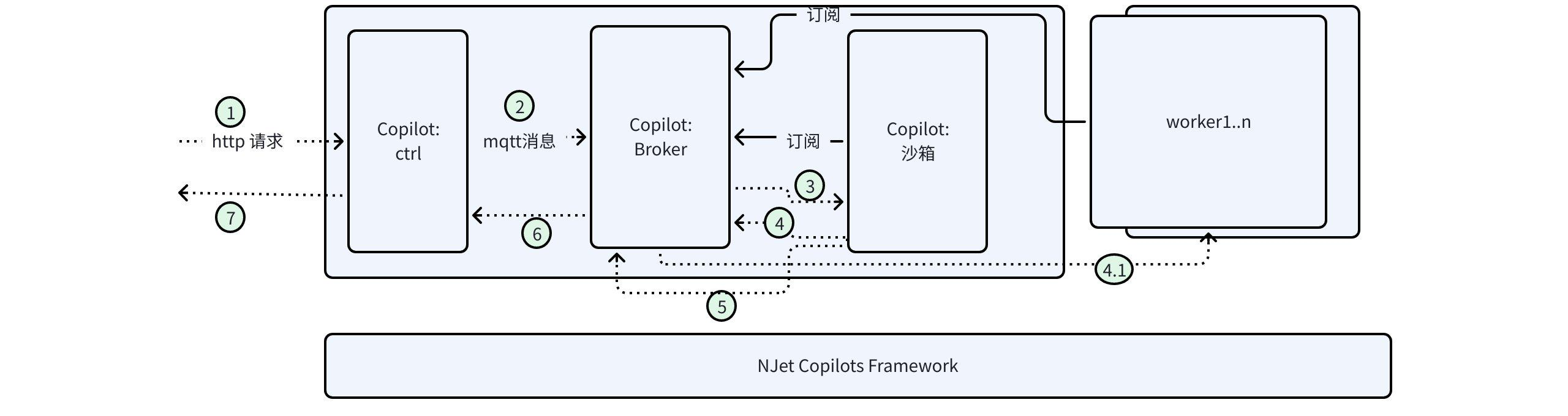
当时的设计初衷是event框架仅仅做简单的api配置变更,假设了这类配置动态变更数量比较少,所以仅仅是功能上的考虑,性能没有做太多要求,所以上图所显示的client发送http请求后,这一套标序号的流程走下来,完成过程是10ms这个级别,平均约50ms。
随着NJet在不同场景的应用,有两个关键性的需求对这套event框架的性能需求提出了严重挑战,第一是实际生产环境的超大规模配置数据;第二是某些业务场景需要快速的worker间数据交换。
- 先说下大规模配置数据的挑战。由于NJet支持server及location级别的动态化,以及可以动态配置上游成员,实际生产中频繁碰到了过百个,甚至1000+上游成员, 而server也有近100级别,因此通过动态api下发配置,常常耗时超过10s,最大的一个客户场景报告超过43s。
- 进程间数据交换来源于NJet作为消息服务器的需求,由于NJet在前期提炼出了一套动态协议框架,可以简单的增加某种协议的解析库,结合tcc脚本实现业务逻辑,就可以快速的实现某种特定协议的应用服务器。以联邦制的消息服务器为例,某client发送一条消息到消息服务器,如果接收者在消息服务器注册,消息服务器会直接处理,否则就需要根据目的地址,转发到其他的消息服务器(注:客户注册到不同的消息服务器,但仍然可以相互通信,称为联邦,比较流行的matrix,以及古老的irc、邮件都是这种模型)。消息服务器间的通信,出于安全等方面考虑,仅仅会维持1条长链接,对NJet这种继承自NGINX的多进程模式就提出了很大挑战,即client发送到消息服务器的消息,可能会被worker1接收,但根据目的选择,需要被worker2发送,因为只有worker2才建立了到合适目的消息服务的连接
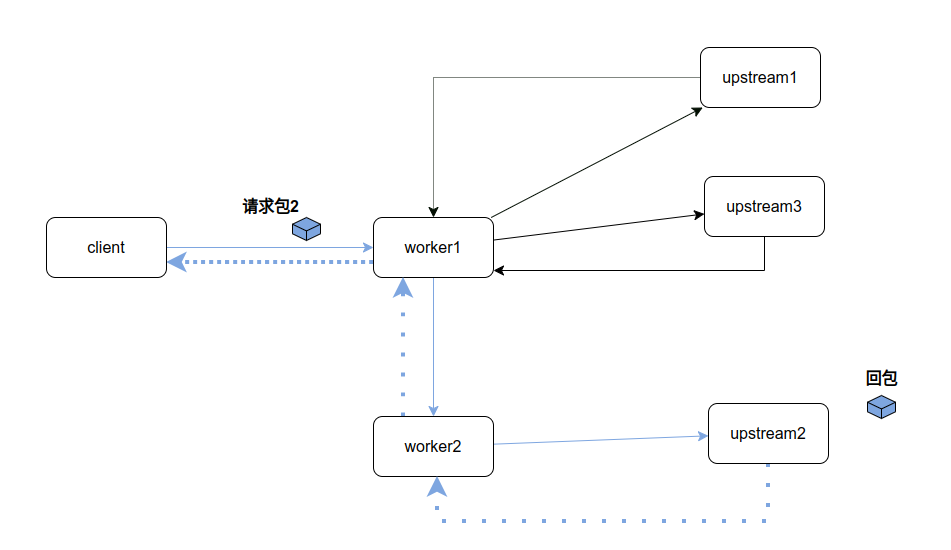
上图所显示的worker1 接收到消息,转发到worker2,以及回包worker2转发到worker1,就采用了NJet内置的event框架,但10ms级别的处理性能,远不能满足消息服务器的处理性能指标要求,甚至由于加入了跨进程通信,出现了多worker处理能力远小于单worker处理能力的荒谬情况
瓶颈分析
njet中集成的mqtt broker来源于mosquitto,NJet基于此做了定制,做了对Copilot框架的适配,从而保证NJet能够管理该broker。在优化了client端代码后(主要是把消息缓冲发送,修改为立即发送),平均的处理时间降低到了2ms(见下图),但这个处理速度,仍然不能满足进程间通信的处理要求。

访问单独的mosquitto不存在性能问题,以及tcpdump抓包发现嵌入CoPilot框架后,broker处理慢,确认了CoPilot框架阻塞了broker对于消息的处理。
根据NJet的Copilot开发指南,独立的Copilot进程应实现自己的事件处理循环(实现函数njt_helper_run),并在该循环中,调用check_cmd_fp,获得NJet的当前状态,如停止,reload等,从而终止事件循环,保证NJet对Copilot进程的管理,对check_cmd_fp的调用分析发现其最终调用了ngx_process_events_and_timers,该函数调用会被IO事件触发,否则会定时一段时间返回,如下面代码显示:
voidngx_process_events_and_timers(ngx_cycle_t *cycle){
ngx_uint_t flags;ngx_msec_t timer, delta;
// 计算最近的定时器超时时间
timer = ngx_event_find_timer();
// 核心阻塞调用
(void) ngx_process_events(cycle, timer, flags);
// 处理定时器ngx_event_expire_timers();}
所以为了保证CoPilot事件循环不被阻塞,就需要保证Copilot进程中特定的ngx_process_events_and_timers调用立即返回(通过设置timer为0)
修复
无独有偶,在我们考虑如何传递参数进ngx_process_events_and_timers时,我们发现了openresty的特定patch
// openrestry patch
if (!njt_queue_empty(&njt_posted_delayed_events)) {
njt_log_debug0(NJT_LOG_DEBUG_EVENT, cycle->log, 0,
"posted delayed event queue not empty"
" making poll timeout 0");
timer = 0;
}
// openresty patch end
通过读Openresty的注释,我们发现了openresty在提供定时器上也存在了被ngx_process_events_and_timers阻塞,定时器性能不高的问题,其解析方案是添加了全局的事件队列,通过向其临时post一条消息,从而保证了接下来的调用可以不被阻塞,立即返回。
所以我们的解决方案就很简单了,在check_cmd_fp向该队列设置一条消息,
......
njt_post_event(param->ev, &njt_posted_delayed_events);
int cmd = param->check_cmd_fp(cycle);
......
感谢openresty!
成效
原api调用压测结果:20条/s
Running 1m test @ http://localhost:8081/api/v1/config
1 threads and 1 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 53.89ms 6.59ms 169.60ms 98.13%
Req/Sec 18.65 3.44 20.00 86.62%
1117 requests in 1.00m, 244.34KB read
Requests/sec: 18.60
Transfer/sec: 4.07KB
改进后的调用结果:10000条/s
Running 1m test @ http://localhost:8081/api/v1/config
1 threads and 1 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 119.09us 212.75us 7.30ms 98.51%
Req/Sec 10.12k 1.12k 12.62k 67.05%
604889 requests in 1.00m, 101.53MB read
Requests/sec: 10064.84
Transfer/sec: 1.69MB
本地测试提高了约500倍,在虚拟机等各种不同的环境也有百倍以上的性能提升,满足了消息服务器等各种跨进程通信的性能需求
备注
- CoPilot开发指南参考:https://docs.njet.org.cn/docs/v4.0.0/development/copilot/index.html
- 本优化在NJet4.0.1版本实现,并backport到长期支持版本3.3.x,请升级到对应的版本3.3.1.2
- NJet会定期从nginx和openresty合并,目前合并nginx到1.27.4